Overview
The development of Multimodal Large Language Models (MLLMs) for real-world applications, such as autonomous driving and robotics, is often constrained by a critical trade-off: computational efficiency versus robust visual reasoning. Large models offer accuracy but are too slow for real-time decision-making, while smaller models lack the necessary visual intelligence for complex, open-world scene understanding.
We address this fundamental challenge through two novel frameworks presented at EMNLP 2025 (LEO-MINI) and NeurIPS 2025 (HAWAII), which collectively create a new class of hyper-efficient and highly capable MLLMs.
-
LEO-MINI focuses on the efficiency bottleneck. It introduces Conditional Token Reduction to drastically reduce visual data redundancy and employs a Mixture of Multi-Modal Experts (MMoE) to enhance reasoning, ensuring the model can process massive visual inputs (like road scenes) in real-time.
-
HAWAII focuses on knowledge acquisition. It utilizes a Hierarchical Visual Knowledge Transfer framework to efficiently distill the specialized, complementary knowledge from multiple pretrained visual experts into a single, compact encoder. This significantly boosts the model's ability to accurately perceive and interpret complex or ambiguous driving conditions.
Together, these projects provide a dual solution for the next generation of visual AI, resulting in MLLMs that are simultaneously faster, smarter, and far more reliable for accelerating road scene understanding and other mission-critical visual tasks.
First project: [EMNLP 2025] LEO-MINI: resolving the MLLM bottleneck with efficient reasoning
TLDR: LEO-MINI is an efficient MLLM architecture that solves the speed bottleneck caused by excessive visual data. It uses Conditional Token Reduction (CoTR) to eliminate redundant visual tokens for fast, real-time processing, and a Mixture of Multi-Modal Experts (MMoE) to selectively boost reasoning capabilities with minimal computational overhead.
In applying Multimodal Large Language Models (MLLMs) to high-throughput visual tasks like road scene analysis, the primary performance roadblock lies not in the LLM itself, but in the overwhelming number of visual tokens generated from high-resolution inputs. LEO-MINI directly tackles this computational bottleneck with a dual strategy focused on radical efficiency and smarter reasoning.
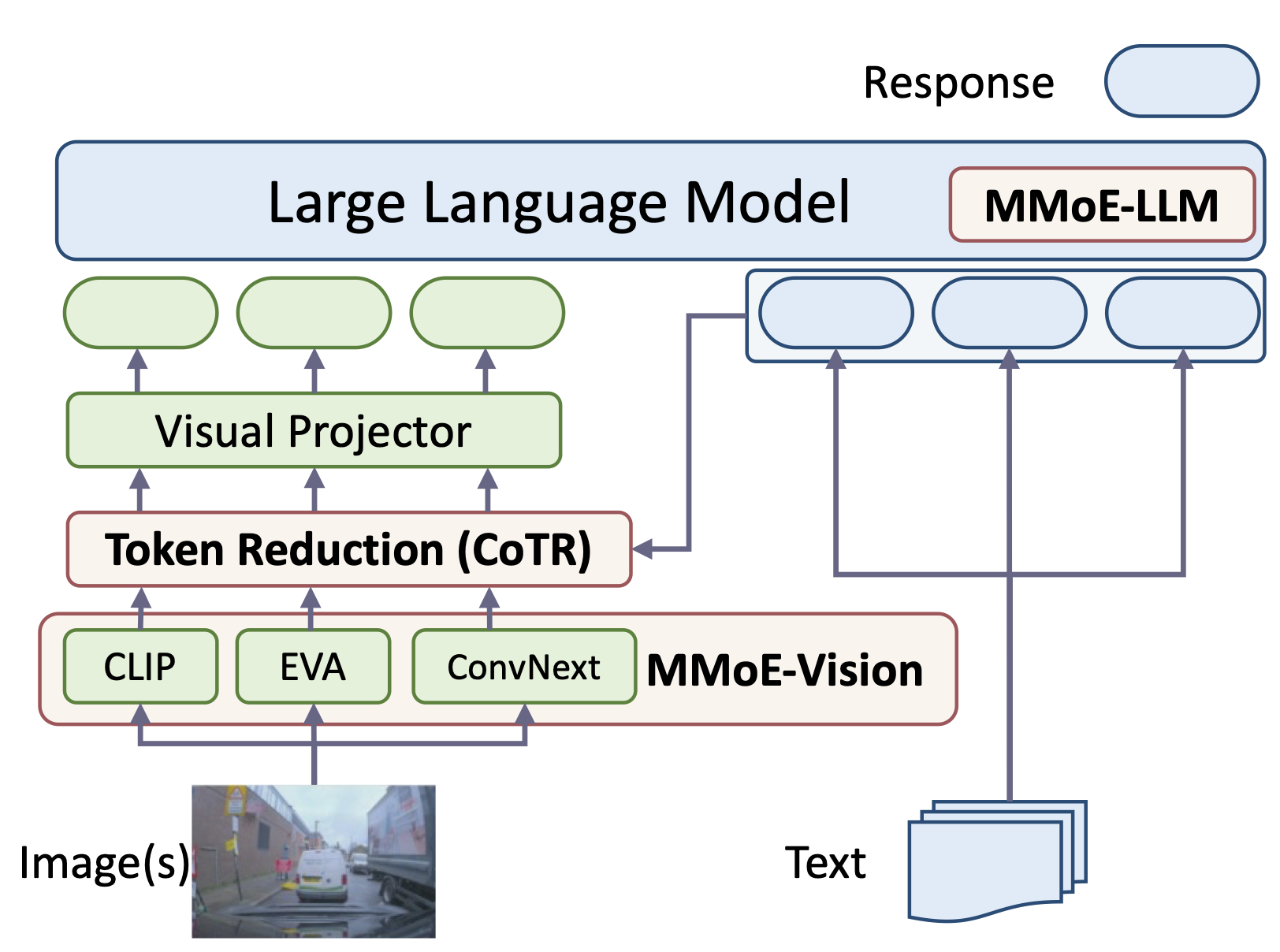
1. Conditional Token Reduction (CoTR): Speed for Real-Time Perception
When an MLLM processes a high-resolution image—such as a dense city street—the vast majority of visual patches contain redundant or low-value information (e.g., a uniform sky or pavement). Processing all these tokens significantly slows down the model, making it unsuitable for the real-time demands of autonomous systems.
CoTR solves this by consolidating the thousands of visual tokens into a small, highly informative set. Crucially, this reduction is conditional: it considers the input visual data alongside the context provided by the textual prompt and a learnable query. This ensures that only the most relevant visual information—like an approaching vehicle or a critical road sign—is retained for the LLM, enabling the model to process complex scenes at speeds viable for real-time applications.
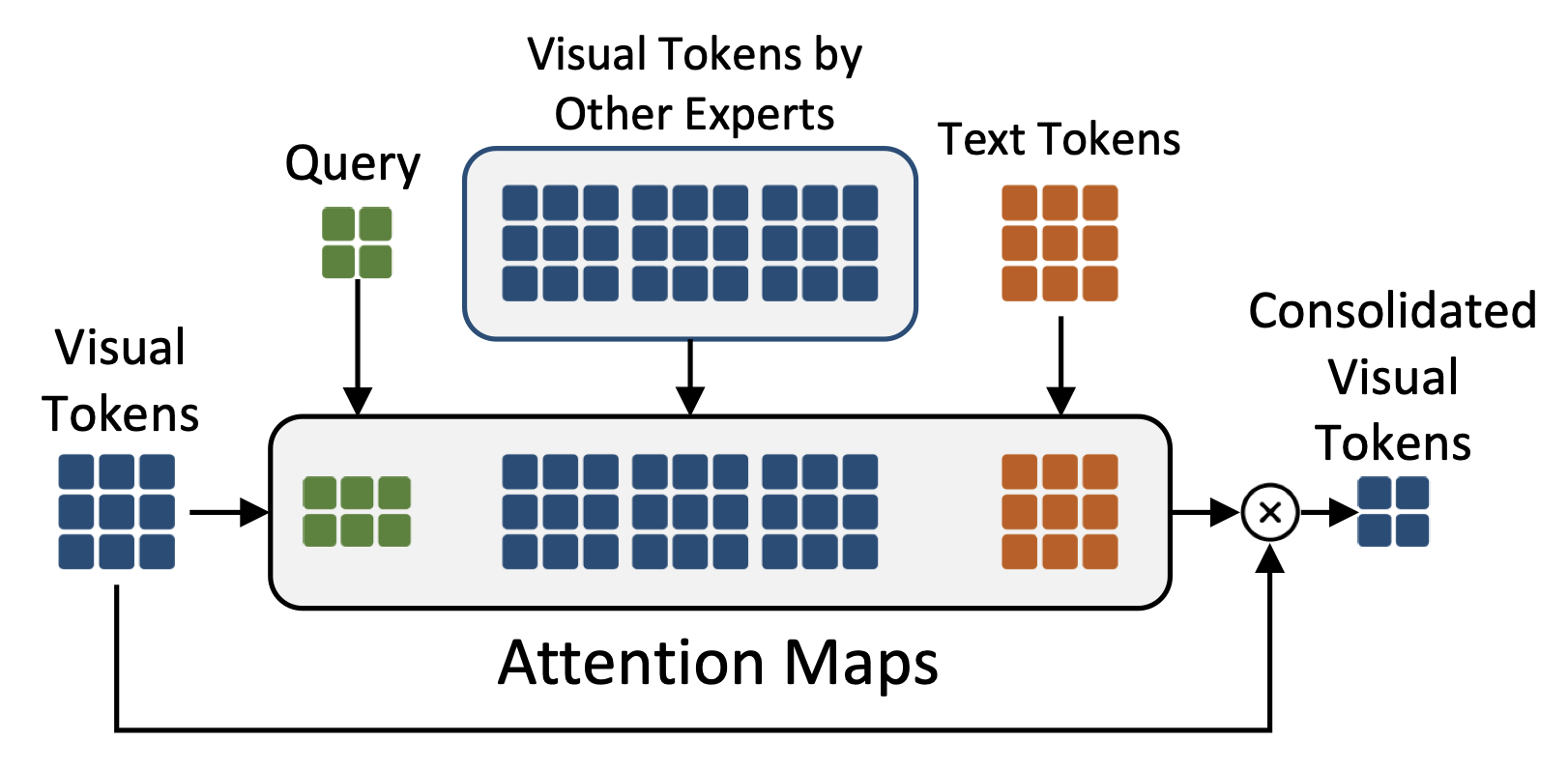
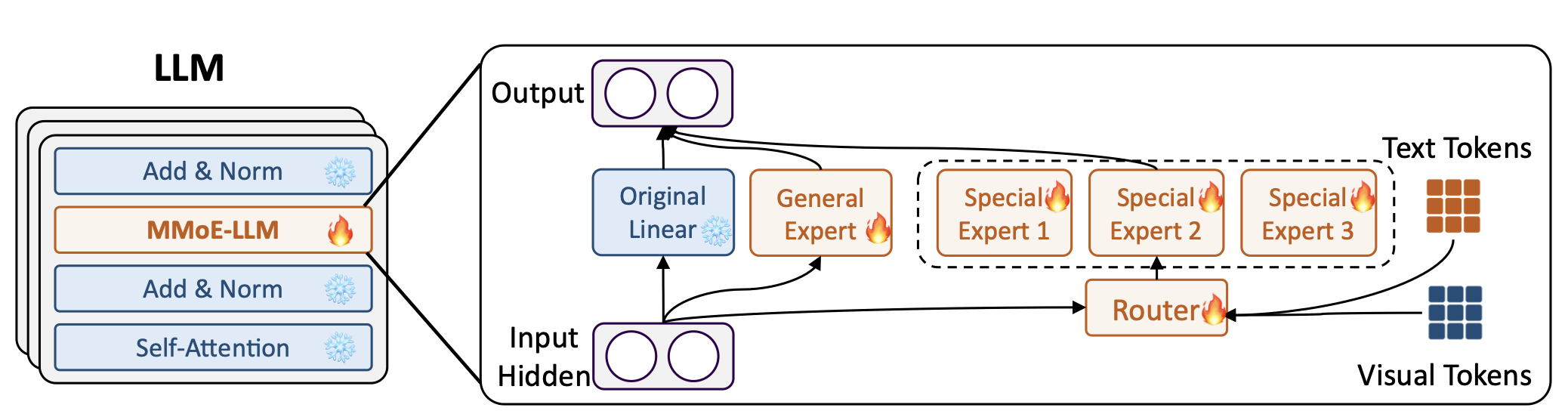
2. Mixture of Multi-Modal Experts (MMoE): Accurate Visual Intelligence
To ensure that efficiency does not come at the expense of accuracy, LEO-MINI integrates a powerful Mixture of Multi-Modal Experts (MMoE). This module allows the model to scale its knowledge without proportional scaling in compute.
The MMoE uses specialized LoRA experts that are dynamically activated by a router informed by both the visual tokens and the text prompt. This differs from traditional MMoE approaches, allowing LEO-MINI to selectively engage the best visual reasoning expert based on the specific scene and question. For instance, an expert specializing in low-light conditions or specific traffic patterns can be dynamically selected, leading to superior and more accurate decision-making in diverse open-world scenarios.
Impact on Road Scene Understanding (LEO-MINI)
The central impact of LEO-MINI lies in transforming MLLMs from high-performing, but slow, research models into deployment-ready solutions for time-critical systems like autonomous vehicles. In road scene understanding, speed is directly linked to safety.
-
Enabling Real-Time Performance: LEO-MINI’s Conditional Token Reduction (CoTR) directly addresses the latency bottleneck. By aggressively and intelligently filtering out redundant visual tokens, the model can process massive amounts of high-resolution camera data at millisecond-level speeds, which is essential for instantaneous decision-making in a fast-moving vehicle.
-
Focusing Attention on Critical Events: CoTR ensures that the model's limited computational budget is spent only on the most informative visual cues. This means the model is less distracted by static background elements and instead prioritizes dynamic, high-risk objects like sudden brake lights, weaving pedestrians, or complex multi-car interactions.
-
Specialized Reasoning on Demand: The Mixture of Multi-Modal Experts (MMoE) allows the model to perform highly specialized visual reasoning (e.g., "Is that person signaling a turn?") without running a computationally heavy model for every single frame. This on-demand, specialized intelligence leads to safer, more nuanced, and highly efficient decision-making in diverse traffic scenarios.
Project 2: [NeurIPS 2025] HAWAII: building robust perception through hierarchical knowledge transfer
TLDR: HAWAII solves the visual knowledge limitation of MLLMs by using Hierarchical Visual Knowledge Transfer to efficiently distill the specialized, complementary strengths of multiple visual expert models into a single encoder, resulting in a model with significantly enhanced and more robust visual understanding.
While LEO-MINI solves the speed problem, HAWAII (Hierarchical Visual Knowledge Transfer) addresses the crucial challenge of robustness and holistic visual knowledge in MLLMs. A general-purpose vision encoder often lacks the diverse, specialized knowledge required to handle the countless variables encountered in real-world scenarios—especially dangerous or rare events on the road.
Hierarchical Knowledge Distillation: The Power of Specialized Experts
HAWAII's core innovation is efficiently aggregating the strengths of multiple specialized visual expert models(teachers) into a single, compact vision encoder (student). Traditional methods of knowledge distillation often lead to conflicts and noise when blending disparate models. HAWAII overcomes this by introducing:
-
Teacher-Specific LoRA Adapters: These adapters are aligned with their respective expert teachers and use a router to prevent conflicting knowledge transfer.
-
Hierarchical Distillation: Knowledge is transferred on two levels:
-
Fine-Grained: Uses token importance scores to adaptively select and learn only the most informative tokens from each expert, ensuring the model focuses on critical, highly-detailed features.
-
Coarse-Grained: Transfers the collective consensus and generalized knowledge from all teachers into the student for a global, foundational alignment.
-
This framework allows the single vision encoder to inherit the robust, complementary strengths of models specializing in different domains—such as object segmentation, fine-grained details, or complex geometry—without the massive computational cost of running all experts simultaneously.
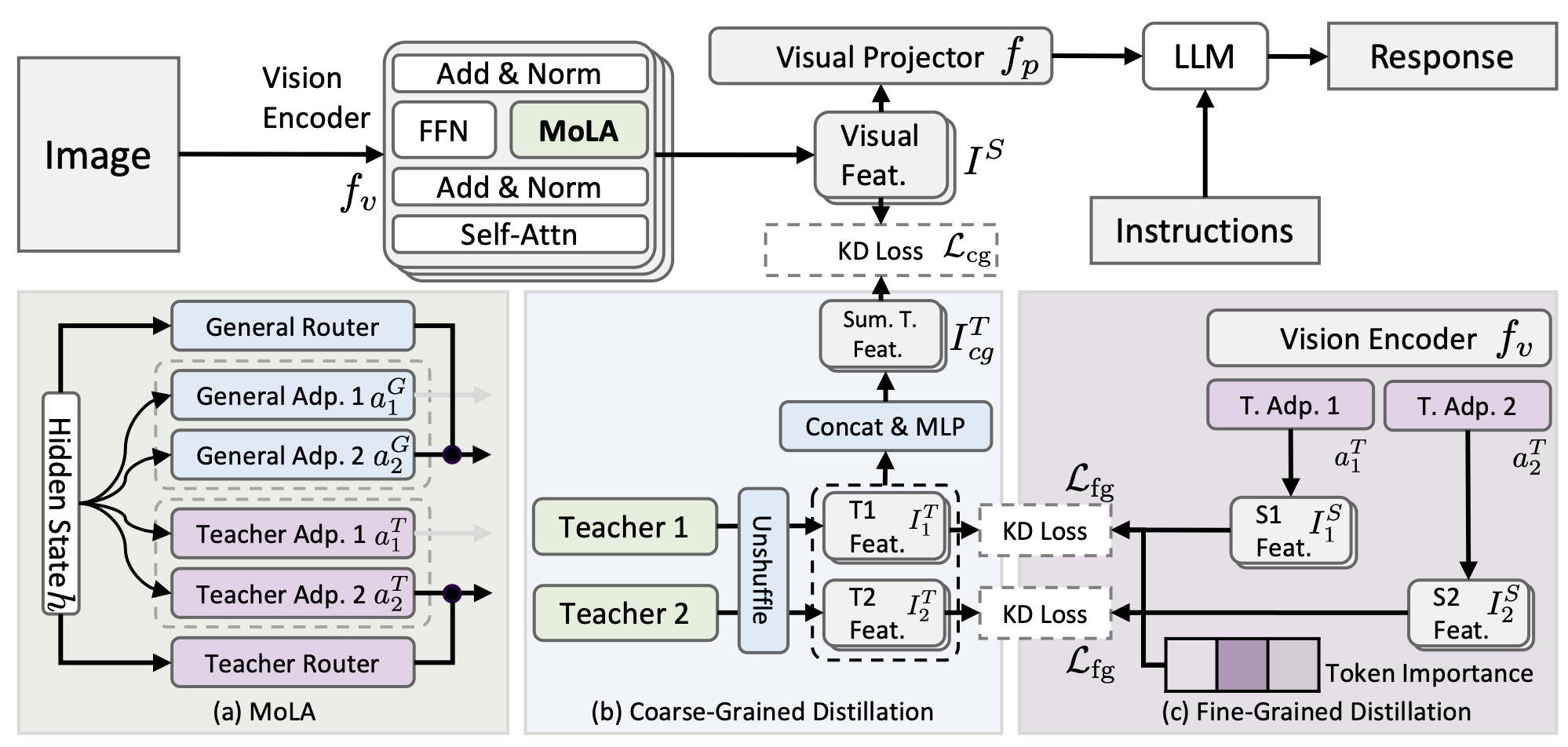
Impact on Road Scene Understanding
The primary impact of HAWAII lies in boosting safety and generalization for autonomous systems:
-
Robustness to Novel Situations: By learning from diverse experts, the single HAWAII-enhanced VLM can better generalize to out-of-distribution scenarios (e.g., unexpected debris, varied lighting, dense crowds) that are critical for safe autonomous navigation but rarely seen in standard training sets.
-
Comprehensive Perception: It moves beyond simple bounding box recognition to integrate fine-grained knowledge (like the difference between a stop sign and a caution sign) and holistic scene understanding, allowing the MLLM to perform deeper reasoning on complex visual queries from the road environment.
-
Efficiency in Inference: Crucially, this robust knowledge is packaged into a single, efficient encoder, meaning the safety and accuracy benefits are achieved without sacrificing the real-time processing speed (which LEO-MINI already maximizes).
Conclusion
The combination of LEO-MINI and HAWAII solves the critical MLLM deployment bottleneck. By simultaneously delivering hyper-efficient speed and robust, expert-level visual knowledge, these two papers accelerate the development of systems capable of safe, real-time interpretation of complex, open-world environments.
Resources
Project pages
Papers
- Yimu Wang, Mozhgan Nasr Azadani, Sean Sedwards, and Krzysztof Czarnecki. 2025. LEO-MINI: An Efficient Multimodal Large Language Model using Conditional Token Reduction and Mixture of Multi-Modal Experts. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 7257–7272, Suzhou, China. Association for Computational Linguistics.
- Yimu Wang, Mozhgan Nasr Azadani, Sean Sedwards, and Krzysztof Czarnecki. 2025. Hawaii: Hierarchical Visual Knowledge Transfer for Efficient Vision-Language Models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems.