Publications
, Accepted. Vector Transport Free Riemannian LBFGS for Optimization on Symmetric Positive Definite Matrix Manifolds. In Asian Conference on Machine Learning (ACML). November. Virtual, p. 8. Available at: http://www.acml-conf.org/2021/conference/accepted-papers/81/.
, 2021. Partially Observable Mean Field Reinforcement Learning. In Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS). 3–7 May. London, United Kingdom: International Foundation for Autonomous Agents and Multiagent Systems, pp. 537-545.
, 2021. Generative locally linear embedding: A module for manifold unfolding and visualization. Software Impacts, 9, p.3.
, 2021. Acceleration of Large Margin Metric Learning for Nearest Neighbor Classification Using Triplet Mining and Stratified Sampling. Journal of Computational Vision and Imaging Systems, 6, p.5. Available at: https://openjournals.uwaterloo.ca/index.php/vsl/article/view/3534.
, 2021. Active Measure Reinforcement Learning for Observation Cost Minimization: A framework for minimizing measurement costs in reinforcement learning. In Canadian Conference on Artificial Intelligence. Springer, p. 12.
, 2021. Analysis of Language Embeddings for Classification of Unstructured Pathology Reports. In International Conference of the IEEE Engineering in Medicine and Biology Society. November. IEEE, p. 4.
, 2021. Batch-Incremental Triplet Sampling for Training Triplet Networks Using Bayesian Updating Theorem. In 25th International Conference on Pattern Recognition (ICPR). January. Milan, Italy (virtual): IEEE, p. 7. Available at: https://ieeexplore.ieee.org/document/9412478.
, 2021. Generative Locally Linear Embedding. Available at: https://arxiv.org/abs/2104.01525.
, 2021. Integrating Affective Expressions into the Search and Rescue Context in order to Improve Non-Verbal Human-Robot Interaction. In Workshop on Exploring Applications for Autonomous Non-Verbal Human-Robot Interactions (HRI). March. Virtual: ACM. Available at: https://sites.google.com/view/non-verbal-hri-2021/home.
, 2021. Magnification Generalization for Histopathology Image Embedding. In IEEE International Symposium on Biomedical Imaging (ISBI). April. p. 5.
, 2021. Prediction and Causality: How Can Machine Learning be Used for COVID-19?. In "What Needs to be done in order to Curb the Spread of Covid-19: Exposure Notification, Legal Considerations, and Statistical Modeling", a Conference on Data and Privacy during a Global Pandemic. July. Waterloo, Canada: Master of Public Service (MPS) Policy and Data Lab, University of Waterloo, p. 6. Available at: https://uwaterloo.ca/master-of-public-service/events/data-and-privacy-during-global-pandemic-conference.
, 2021. Quantile–Quantile Embedding for Distribution Transformation and Manifold Embedding with Ability to Choose the Embedding Distribution. Machine Learning with Applications (MLWA), 6.
, 2021. Recognition of a Robot's Affective Expressions under Conditions with Limited Visibility. In 18th International Conference promoted by the IFIP Technical Committee 13 on Human–Computer Interaction (INTERACT 2021). September. Bari, Italy, p. 22.
, 2020. A review of machine learning applications in wildfire science and management. Environmental Reviews, 28(3), p.73. Available at: https://www.nrcresearchpress.com/doi/10.1139/er-2020-0019#.X1jbKtNKhTY.
, 2020. Isolation Mondrian Forest for Batch and Online Anomaly Detection. IEEE International Conference on Systems, Man, and Cybernetics (SMC) 2020. Available at: arXiv preprint arXiv:2003.03692.
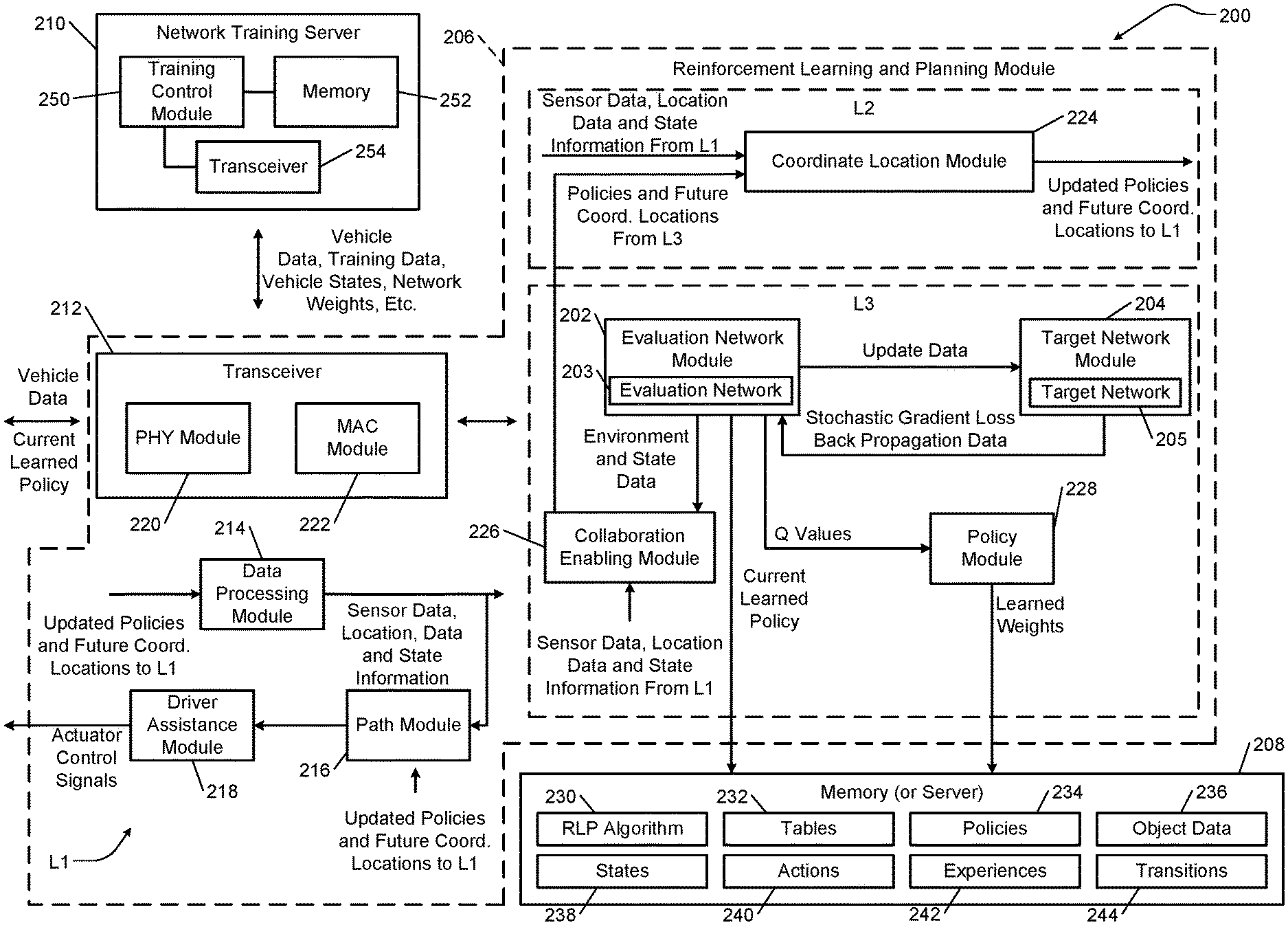
, 2020. Multi-Level Collaborative Control System With Dual Neural Network Planning For Autonomous Vehicle Control In A Noisy Environment. , US11131992B2(US Patent Office). Available at: https://patents.google.com/patent/US11131992B2/en.
{kind=link}
, 2020. Offline versus Online Triplet Mining based on Extreme Distances of Histopathology Patches. In International Conference on Intelligent Systems and Computer Vision (ISCV 2020) . Fez-Morrocco (virtual): IEEE, p. 8. Available at: https://arxiv.org/abs/2007.02200.
, 2020. Using Emotions to Complement Multi-Modal Human-Robot Interaction in Urban Search and Rescue Scenarios. In 22nd International Conference on Multimodal Interaction (ICMI-2020). October. Utrecht, the Netherlands, p. 9.
, 2020. Supervision and Source Domain Impact on Representation Learning: A Histopathology Case Study. In International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC'20). 42nd Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC'20): IEEE Engineering in Medicine and Biology Society. Available at: https://embs.papercept.net/conferences/scripts/rtf/EMBC20_ContentListWeb_1.html#moat2-15_02.