I have noticed that Bigtable, HBase, Hypertable, and Cassandra are being called column-stores with increasing frequency (e.g. here, here, and here), due to their ability to store and access column families separately. This makes them appear to be in the same category as column-stores such as Sybase IQ, C-Store, Vertica, VectorWise, MonetDB, ParAccel, and Infobright, which also are able to access columns separately. I believe that calling both groups of systems column-stores has lead to a great deal of confusion and misplaced expectations. This blog post attempts to clear up some of this confusion, highlighting the high level differences between these groups of systems. At the end, I will propose some potential ways to rename these groups to avoid confusion in the future.
For this blog post, I will refer to the following two groups as Group A and Group B:
- Group A: Bigtable, HBase, Hypertable, and Cassandra. These four systems are not intended to be a complete list of systems in Group A --- these are simply the four systems I understand the best in this category and feel the most confident discussing.
- Group B: Sybase IQ, C-Store, Vertica, VectorWise, MonetDB, ParAccel, and Infobright. Again, this is not a complete list, but these are the systems from this group I know best. (Row/column hybrid systems such as Oracle or Greenplum are ignored from this discussion to avoid confusion, but the column-store aspects of these systems are closer to Group B than Group A.)
Differences between Group A and Group B
- Data Model. Group A uses a multi-dimensional map (something along the lines of a sparse, distributed, persistent multi-dimensional sorted map). Typically a row-name, column-name, and timestamp are sufficient to uniquely map to a value in the database. Group B uses a traditional relational data model. This distinction has caused great confusion. People more familiar with Group A are very much aware that Group A does not use a relational data model and assume that since Group B are also called column-stores, then Group B also does not use a relational data model. This has resulted in many intelligent people saying “column-stores are not relational”, which is completely incorrect.
- Independence of Columns. Group A stores parts of a data entity or “row” in separate column-families, and has the ability to access these column-families separately. This means that not all parts of a row are picked up in a single I/O operation from storage, which is considered a good thing if only a subset of a row is relevant for a particular query. However, column-families may consist of many columns, and these columns within column-families are not independently accessible.
Group B stores columns from a traditional relational database table separately so that they can be accessed independently. Like Group A, this is useful for queries that only access a subset of table attributes in any particular query. However, the main difference is that every column is stored separately, instead of families of columns as in Group A (this statement ignores fine-grained hybrid options within Group B).
- Interface. Group A is distinguished by being part of the NoSQLmovement and does not typically have a traditional SQLinterface. Group B supports standard SQL interfaces.
- Optimized workload. Group B is optimized for read-mostly analytical workloads. These systems support reasonably fast load times, but high update rates tend to be problematic. Hence, data warehouses are an ideal market for Group B, since they are typically bulk-loaded, require many complex read queries, and are updated rarely. In contrast, Group A can handle a more diverse set of application requirements (Cassandra, in particular, can handle a much higher rate of updates). Group B systems tend to struggle on workloads that “get” or “put” individual rows in the data set, but thrive on big aggregations and summarizations that require scanning many rows as part of a single query. In contrast, Group A generally does better for individual row queries, and does not perform well on aggregation-heavy workloads. Much of the reason for this difference can be explained in the “pure column” vs “column-family” difference between the systems. Group A systems can put attributes that tend to be co-accessed in the same column-family; this saves the seek cost that results from column-stores needing to find different attributes from the same row in many different places. Another reason for the difference is the storage layer implementation, explained below.
- Storage layer. Assume the following customer table
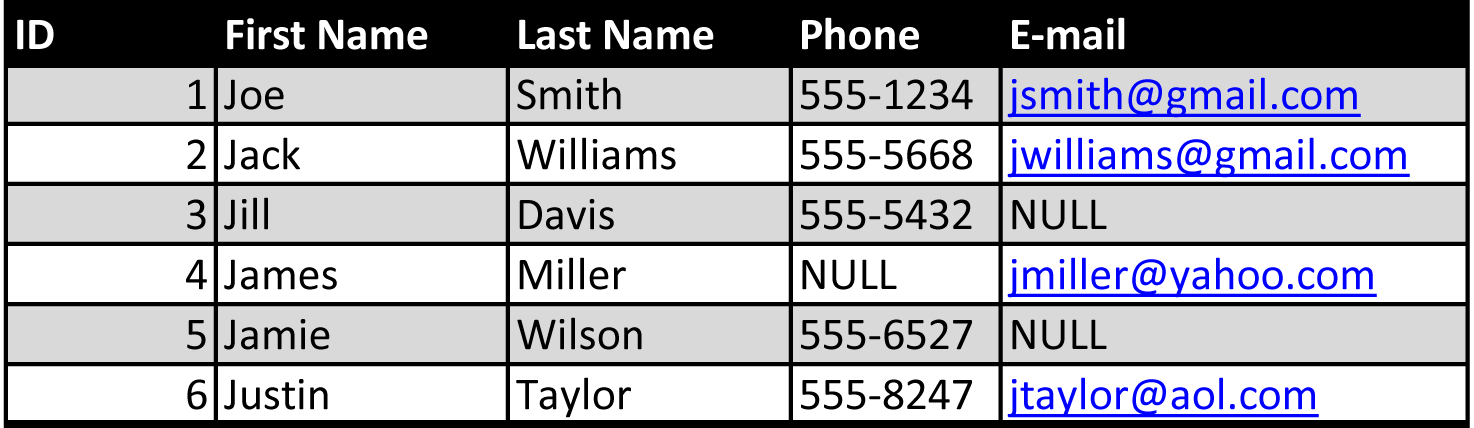
Although there is some variation within the systems in Group B, to the first order of approximation, this group will store the table in the following way:
(ID) 1, 2, 3, 4, 5, 6
(First Name) Joe, Jack, Jill, James, Jamie, Justin
(Last Name) Smith, Williams, Davis, Miller, Wilson, Taylor
(Phone) 555-1234, 555-5668, 555-5432, NULL, 555-6527, 555-8247
(Email) jsmith@gmail.com, jwilliams@gmail.com, NULL, jmiller@yahoo.com, NULL, jtaylor@aol.com
Note that each value is stored by itself, without information about what row or column it came from. We can figure out what column it came from since all values from the same column are stored consecutively. We can figure out what row it came from by counting how many values came before it in the same column. The fourth value in the id column matches up to the same row as the fourth value in the last name column and the fourth value in the phone column, etc. Note that this means that columns that are undefined for a particular row must be explicitly stored as NULL in the column list; otherwise we can no longer match up values based on their position in their corresponding lists.
Meanwhile, systems in Group A will either explicitly store the row-name, the column-name or both with each value. E.g.: row2, lastname: Williams; row5, phone: 555-6527, etc. The reason is that Group A uses a sparse data model (different rows can have a very different set of columns defined). Storing NULLs for every undefined column could soon lead to the majority of the database being filled with NULLs. Hence these systems will explicitly have column-name/value pairs for each element in a row within a column-family, or row-name/value pairs for each element within a single column column-family. (Group A will also typically store a timestamp per value, but explaining this will only complicate this discussion).
This results in Group B typically taking much less space on storage than Group A (at least for structured data that easily fits into a relational model). Furthermore, by storing just column-values without column-names or row-names, Group B optimizes performance for column-operations where each element within a column is read and an operation (like a predicate evaluation or an aggregation) is applied. Hence, the data model combined with the storage layer implementation results in wildly different target applications for Group A and Group B.
Renaming the Groups
Clearly along each of these five dimensions, Group A and Group B are extremely different. Consequently, even though calling them both column-stores has some advantages (it makes it seem like the “column-store movement” is large and a really hot area), I believe that lumping Group A and Group B together does more damage than good, and that we need to make a greater effort to avoid confusing these two groups in the future. Here are some suggestions for names for Group A and Group B towards this goal:
- Group A: “column-family store”
Group B: “column-store”
(The problem here is that Group B doesn’t get a new name, which means that “column-store” could either refer to Group B or both Group A/B)
- Group A: “non-relational column-store”
- Group B: “relational column-store”
- Group A: “sparse column-store”
- Group B: “dense column-store”
Of these, the relational/non-relational distinction is probably the most important, and would be my vote for the new names. If you have a different idea for names, or want to vote on one of the above schemes, please leave a comment below.
Addendum:
Mike Stonebraker e-mailed me his vote which I reproduce here with his permission:
Group A are really row stores. I.e. they store a column family in a row-by-row fashion. Effectively, they are using materialized views for column families and storing materialized views row-by-row. Systems in Group B have a sophisticated column-oriented optimizer -- no such thing exists for Group A.
He
then
went
on
to
call
Group
A
"MV row-stores"
and
sub-categorize
Group
B
depending
on
how
materialized
views
are
stored,
but
his
overarching
point
was
that
referring
to
anything
in
Group
A
as
a
"column-store"
is
really
misleading.
Addendum
2:
This
post
seems
to
have
attracted
some
high
quality
comments.
I
recommend
reading
the
comment
thread.