Thursday, April 19, 2018
 The following is a post by Professor Ihab Ilyas, a member of the Data Systems Group and the Thomson Reuters Research Chair in Data Cleaning from Theory to Practice.
The following is a post by Professor Ihab Ilyas, a member of the Data Systems Group and the Thomson Reuters Research Chair in Data Cleaning from Theory to Practice.
This article appeared originally on ACM SIGMOD Blog, the official blog of the Association for Computing Machinery's Special Interest Group on Management of Data.
When dealing with real-world data, dirty data is the norm rather than the exception. We continuously need to predict correct values, impute missing ones, and find links between various data artefacts such as schemas and records. We need to stop treating data cleaning as a piecemeal exercise (resolving different types of errors in isolation), and instead leverage all signals and resources (such as constraints, available statistics, and dictionaries) to accurately predict corrective actions.
The primary goal of data cleaning is to detect and remove errors and anomalies to increase the value of data in analytics and decision making. While it has been the focus of many researchers for several years, individual problems have been addressed separately. These include missing value imputation, outliers detection, transformations, integrity constraints violations detection and repair, consistent query answering, deduplication, and many other related problems such as profiling and constraints mining.In this post, I advocate for a new way to look at the problem, and highlight challenges our community is best suited to tackle to make a lasting impact.
Where are the solutions?
While it is easier for the scientific community to formulate and tackle these problems in isolation, in reality they are never present that way. Most dirty datasets suffer from most or all of these problems, and they interact in non-trivial ways. For example, we can’t find duplicates effectively without mapping schemas, wrangling data sources, imputing missing values, and removing outliers. Studies such as the one here show that there is no clear magical order of the “right” sequence of cleaning exercises due to their dependency. Even when applied all, the recall and precision of union is poor because none has captured the “holistic” nature of the data cleaning process.
To add more bad news, the interaction between these error types is not the only problem. First, most of the techniques don’t scale well. They either have quadratic complexity or require multiple passes on the whole dataset. Second, most of the parameters of these tools are hard to configure or are non-existent. For example, integrity constraints-based cleaning (survey) requires a rich set of functional dependencies or even richer forms (such as denial constraints) that are seldom available in practice. Third, data are often processed in pipelines, and while errors are easily spot downstream near final reports, data sources are the ones the need fixing, which means maintaining and navigating complex provenance information across heterogeneous systems (check SMOKE, a recent system that tackles this problem). Fourth, adding humans in the loop is a precondition for adopting data cleaning solutions to tune, verify and approve the various automatic decisions.
These challenges — and many other pragmatic reasons — are behind the rarity of deployable and industry-strength data cleaning solutions. The gap between data cleaning solutions used in large enterprises and what the scientific community publishes in terms of assumptions, setup and applicability expands daily. Based on my experience with real data cleaning customers over the past five years, the real competitor of the academic proposals are millions of lines of code in scripts and case-specific wrangling rules written by IT departments struggling to solve their business problems.
Data cleaning as a large-scale machine learning problem
The good news is enterprises are starting to appreciate the need for scalable and principled cleaning solutions as opposed to their home-grown rule-based systems, which started to be a major technical debt and a burden to maintain. The scientific community is also getting better at understanding the real data cleaning challenges (including the engineering and pragmatic ones) because of the recent work of companies like Alation, Tamr, and Trifacta and open-source tools like Magellan, which are used by a number of businesses and enterprises.
Among all these challenges three are the most difficult to overcome but they have the highest impact in delivering usable solutions: (1) considering all types of data errors and problems in a holistic way; (2) scaling to large data sets; and (3) having humans as an integral part of the equation and not only as external verifiers.
I argue that treating the data cleaning problem as a large-scale machine learning problem is principled and an obvious way to address these issues. A principled probabilistic framework can serve as the much needed “melting pot” for all the signals of errors, and the correlation and dependencies among these signals.
Repairing records is mainly about “predicting” the correct value(s) of erroneous or missing attributes in a source data record. The key is to build models that take into account all possible “signals” in predicting the missing or erroneous values. For example, in the HoloClean system (paper and source repo), each cell in a source table is a random variable. Dictionaries, reference datasets, available quality rules, trusted portions of the data are all leveraged to predict the “maximum likelihood” value for these random variables (Figures 1 and 2).
The HoloClean model addresses the “holistic cleaning” problem well from a modelling and representation point of view, allowing all these signals that we have been considering in isolation to interact and guide the data prediction process. However, the engineering challenges remain and include scale, managing and generating training data, running the inference problem efficiently, and involving users in an effective way. These are challenges that the data management research community knows well and is well-suited to solve.
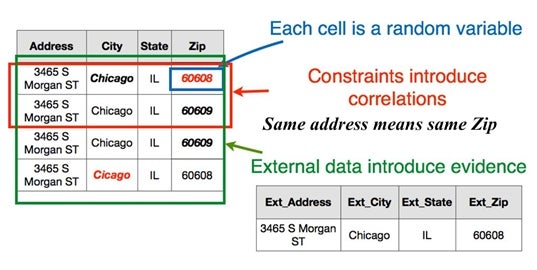
Figure 1: HoloClean compiles signals from a variety of sources to feed a probabilistic inference engine to repair data
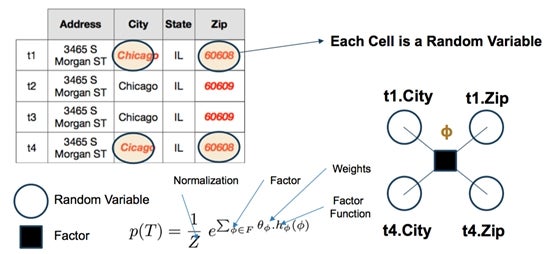
Figure 2: Repair as inference problem
Supervising and scaling ML systems for cleaning
1) Weak supervision to get training data: The legacy of traditional approaches to data integration has left companies with many person-years of encoding business rules, which collectively represent the institutional memory and the written domain knowledge in the enterprise. Ignoring this legacy is usually a non-starter and a main cause of disconnect between the solution provider and the use case owner. A concrete machine learning (ML) challenge is how to “absorb” and “compile” all available rules into signals and features that bootstrap and guide the learning process. The obvious choice of using available rules and scripts to generate training data, while plausible, faces multiple technical challenges. These include how to avoid building a biased model, how to reason about the quality of the training data generated this way, and how to learn from such noisy training data. Recent research in ML, such as the Snorkel project, addresses some of these points via weak-supervision, where rules with different accuracies and sometime overlapping coverage are used to generate large amounts of training data, used to train supervised ML models for a given task. Multiple systems such as Tamr, Trifacta, and HoloClean use weak-supervision principles to increase their repository of training data and to power their ML models for deduplication (as in Tamr), transformations (as in Trifacta) or for general enrichment and structured predictions (as in HoloClean).
2) Scaling ML systems: Dealing with large-scale data sources is one of the main challenges in applying ML models to cleaning. Unlike analytics on a specific vertical or specific data source, data cleaning often involves running inference or prediction on a massive scale. Take for example the deduplication problem. Since we are running a matching classifier on pairs of records, the problem is fundamentally of quadratic complexity: to deduplicate 1M records, we need to run our classifier on O(10^12) feature vectors representing the similarities between every pair (see Figure 3). The problem is not easily parallelizable because of the cross comparison and shuffling needed. Hence, well-engineered solutions that focus on cutting this complexity using techniques like sampling, locality-sensitive hashing, blocking, and optimal distributed joins are effective scalability tools.
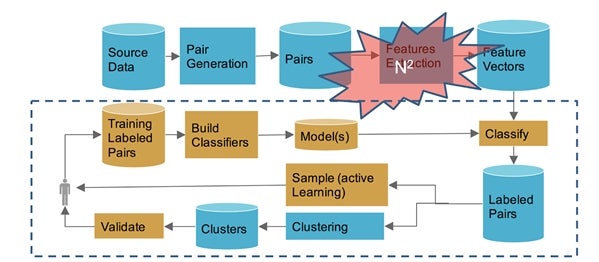
Figure 3: A machine learning pipeline for record deduplication
As another example, consider HoloClean, which predicts data updates by treating each cell in a table as a random variable and runs inference on millions of these random variables, an approach that will be break most off-the-shelf inference engines. Applying an extensive set of technologies to scale out probabilistic inference is a hard challenge. Figure 4 shows a simple HoloClean architecture, where grounding the model, which involves (partially) materializing possible values that a random variable can take, is both an ML and a data management problem. To address this problem, various algorithms that the database community understand well can come to the rescue. These include (1) domain pruning and ranking the most probable values a certain database cell can take; (2) relaxing hard constraints such as denial constraints and functional dependencies to allow for reasoning about each random variable independently; and (3) implementing the various modules using efficient distributed algorithms for joins, large matrix multiplication, caching and many other data systems tricks.
3) Bringing humans in the loop: In supervised models, humans are often used to manually label training data or to verify test data of the model for accuracy. In data cleaning, however, there isn’t “one human” role that fits all.
- Domain experts have to communicate their knowledge of high-level language or rules, or provide training for hard cases (such as rare classification, or non-obvious duplicates)
- ML experts have to manage the ML models and tune the increasing complex ML pipelines
- Data systems administrators have to manage the large-scale source data sets often scattered across servers and in various modalities (JSON, structured in different engines, text, etc)
- Data cleaning experts have to help translate these rules and reason about the various signals that will contribute to finding and repairing errors
- Data scientists have to control things like the required sample size for their predictions, the right data set to use, and the amount of cleaning they require based on the sensitivity of their analytics task to dirty data.
For any deployable cleaning system, all these human roles need to work together via well-specified interaction points with the cleaning tools.
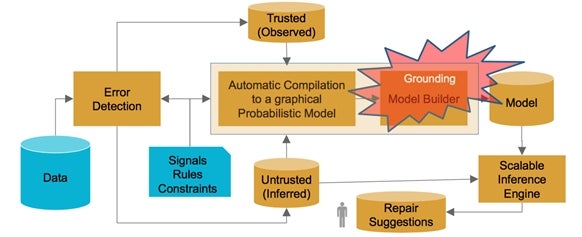
Figure 4: Grounding machine learning models for cleaning is a scalability bottleneck
Luckily, the data community has been increasingly investing in proper and principled ways to bring humans in the loop for data management tasks, creating bridges between the DB and the HCI communities. Examples include the Falcon project for scaling crowdsourcing for entity matching and deduplication; Tamr's heavy use of multiple user roles to guide scheme mapping and record linkage; and visualization systems such as Zenvisage, Vizdom and GestureDB to visualize and interact with large data sets. Integrating these intuitive user interactions for exploration presents great potential to better empower and guide data cleaning systems.
Departing thoughts
In summary, human-guided scalable ML pipelines for data cleaning are not only needed but might be the only way to provide complete and trustworthy data sets for effective analytics. However, several challenges exist. I discussed a few in this post, but by no means is the list complete. While I argued that we should stop dealing with data cleaning as a set of isolated database problems, I am also advocating that database techniques and research are essential to provision functional ML pipelines for cleaning. Of course, this post is not the first to make this general observation. Recent tutorials such as the one by Google in SIGMOD 2017 on “Data Management Challenges in Production Machine Learning” and the one in SIGMOD 2018 on “Data Integration and Machine Learning” highlight the awareness of the various ways data management are used for ML pipelines and how ML can help with some hard data management problems. I think data cleaning is the poster child for ML/DB synergy.
Blogger's profile
Ihab Ilyas is a professor in the David R. Cheriton School of Computer Science at the University of Waterloo, where his main research is in the area of data management, with special interest in big data, data quality and integration, managing uncertain data, and information extraction. Ihab is also a co-founder of Tamr, a startup focusing on large-scale data integration and cleaning.
He is a recipient of an Ontario Early Researcher Award (2009), a Cheriton Faculty Fellowship (2013), an NSERC Discovery Accelerator Award (2014), and a Google Faculty Award (2014). He is an ACM Distinguished Scientist. Ihab is also an elected member of the VLDB Endowment board of trustees, the elected vice chair of ACM SIGMOD, and an associate editor of the ACM Transactions on Database Systems (TODS). He is also the recipient of the Thomson Reuters Research Chair in Data Quality at the University of Waterloo. He received his PhD in computer science from Purdue University, West Lafayette.




