Developed by: Andriana Vanezi, Information Security Services, IST
Preamble by: Ian Milligan, Associate Vice-president, Research Oversight and Analysis
Last updated: May 20, 2025
Preamble
The University of Waterloo, through its Research Data Management (RDM) Institutional Strategy, aims to support research excellence through the provision of excellent RDM services, tools, and supports. In Canada, the Tri-Agencies argue that research data collected using public funds should be responsibly and securely managed and be—where ethical, legal, and commercial obligations allow—available for reuse by others. To this end, the agencies support the FAIR (Findable, Accessible, Interoperable, and Reusable) guiding principles for research data management and stewardship, when appropriate.
Data management, the storage, access, and preservation of data produced from a given research project, is thus a critical component of research activities. Data management practices cover the entire lifecycle of the data, from planning the investigation to conducting it, and from backing up data as it is created and used to long-term preservation of data deliverables after the research investigation has concluded.
In the RDM strategy, the University notes that this strategy was “relevant to all research utilizing and producing research data in all forms (including, but not limited to, digital, analogue, paper, and physical materials)—whether funded or unfunded, published or unpublished, open or restricted.”
Researchers may have questions about whether their data are “open or restricted,” and how they should responsibly steward this information. Canadian research funders, and their institution, want to help researchers share their data (where appropriate) for the advancement of science; we hope this guide helps researchers navigate this landscape.
Purpose
This page provides University of Waterloo (UW) researchers with a standardized framework for classifying research data. By standardizing the classification of research data, a mutual understanding of the associated risk levels is established. This shared framework facilitates effective communication and collaboration among impacted/interested parties, with an institutionally accepted classification. Researchers can identify and engage expertise who can provide meaningful and appropriate support tailored to the specific needs associated with the data risk classification. This collaborative and standardized approach enhances the overall data governance structure, promoting a cohesive effort in safeguarding research data and maintaining compliance with regulatory standards and contractual obligations to research sponsors, when applicable.
While the University of Waterloo’s Policy 46 Information Confidentiality Classification is aligned with the Freedom of Information and Protection of Privacy Act (FIPPA), to protect data used for teaching, learning, and research administration, it was not designed to classify research data. However, the research data risk classification will align with the confidentiality classification outlined in Policy 46, allowing the proposed security controls to be effectively applied across both classifications. See Guidance on Information Confidentiality Classification (Policy 46) | Information Systems & Technology | University of Waterloo. For more details on what constitutes research data, including its definition and examples, see Research Data and Information Not Considered Research Data.
Information Systems & Technology/Information Security Services (ISS/IST) in consultation with Research Data Management Institutional Strategy Working Group, has developed a six (6) step framework to provide researchers with a structured approach to classifying their research data by assessing the potential harm that could arise from compromises. Please see the full document:
Research data risk classification
The Research Data Classification System is based on two main factors: the type of data and the potential gravity of harm that could arise from a compromise.
In cases of ambiguity in research data classification, the higher risk category should be applied. If uncertainty persists, please contact Information Security Services for guidance. For assistance with classifying human participant data, please contact the Office of Research Ethics.
Low
Research data are open or publicly available, a compromise to the integrity or availability of data would cause minimal harm to impacted/interested parties.
Examples (not exhaustive):
|
TYPE OF DATA |
POTENTIAL HARM - MILD |
|---|---|
|
|
Medium
Research data are typically confidential, even if they are not specifically potentially governed by domestic or foreign laws or industry regulations; any compromise to the confidentiality, integrity or availability could lead to mild-to-moderate harm to impacted/interested parties.
Examples (not exhaustive):
|
TYPE OF DATA |
POTENTIAL HARM - MILD TO MODERATE |
|---|---|
|
|
High
Research data are confidential and/or potentially governed by domestic or foreign laws or industry regulations; a compromise to the confidentiality, integrity or availability of data would cause significant harm to impacted/interested parties.
Examples (not exhaustive):
|
TYPE OF DATA |
POTENTIAL HARM – SIGNIFICANT |
|---|---|
|
|
Very High
Research data are confidential, and/or potentially governed by domestic or foreign laws or industry regulations, or Indigenous data sovereignty, and any compromise to the confidentiality, integrity or availability of data could cause serious harm to impacted/interested parties.
Examples (not exhaustive):
|
TYPE OF DATA |
POTENTIAL HARM - SERIOUS |
|---|---|
|
|
Roles and responsibilities
Policy 46 – Information Management outlines distinct roles and responsibilities for research team members. Under this policy, the Principal Investigator or Faculty Supervisor for research projects is the information steward for the research data while other research team members for the research project are information custodians. There may be times when this approach is different, for example, in the context of when researchers are engaging with Indigenous communities.
Engage expertise
Identify individuals or teams within the University of Waterloo who can provide guidance on various aspects of the research project regarding data management (e.g., IT specialists, legal advisors, data management experts).
Map the data lifecycle
The Research Data Lifecycle acts as a roadmap for researchers, outlining key considerations for Research Data Management (RDM) at each stage.
Researchers should also consider the extent to which the data are interconnected with other systems or datasets. This assessment helps identify the potential impact of a data breach or exploit on other parts of the research ecosystem and highlights key impacted/interested parties and their roles in managing and protecting the data throughout its lifecycle.
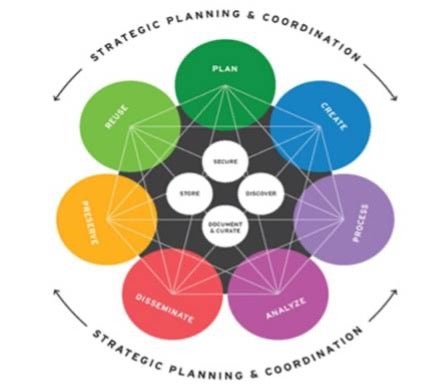
Research data lifecycle phases
Plan: organize research data for discovery, reuse, and archiving and creating a data management plan (DMP).
Create: identify, acquire, and generate research data and metadata.
Process: data are prepared for analysis through validation and cleaning.
Analyze: analyze prepared data.
Disseminate: share findings.
Preserve: transition data to an archival state.
Reuse: ensure data are discoverable and accessible for integration into new datasets.
The following elements need to be considered at each phase of the research data lifecycle and should be integrated into the DMP; the specific implementation of these elements will vary based on the assessed risk level classification of the data.
- Store: The active and archival storage of data, with an emphasis on accessibility and security.
- Discover: Ensuring data discoverability to facilitate accessibility and mobilization for future research use.
- Document and Curate: Providing rich descriptions of data context.
- Secure: Addressing consent, ethical considerations, and maintaining integrity while utilizing established security platforms and guidance from privacy and IT security services.
Research data classification framework
How is risk calculated?
Considering the value of research data and its appeal to malicious actors, it is essential to align handling protocols, processes, and security controls with the assigned data classification. Researchers, with support from campus experts, must identify vulnerabilities and apply targeted cybersecurity measures to ensure data protection and reliable research outcomes. These efforts are critical to maintaining public trust and preserving the integrity of the research process.
Risk assessment involves evaluating threats to research and infrastructure, data exposure, and the impact of unauthorized disclosure, modification, or inaccessibility, forming the foundation for effective risk management.
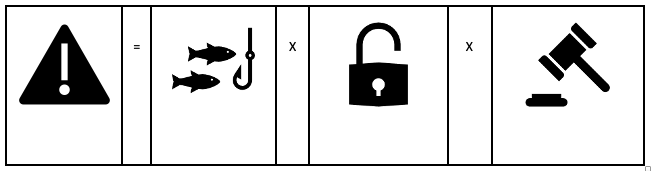
To calculate risk effectively, researchers must assess the following key factors:
- Threat: Any potential danger that could exploit a vulnerability to cause harm to an asset. This can include malicious actors, natural disasters, or system failures.
- Exposure: How exposed or available are the data to threats, or potential threats.
- Impact: The potential consequences or damage that could result from a successful exploit. This includes financial losses, reputational damage, legal implications, and operational disruptions.
Research data classification framework
For full details, please see:
.
- Determine the Scope: Identify the following:
- Impacted/interested parties
- Data types
- Map the Research data lifecycle
- Identify the compliance obligations: University of Waterloo Policies, Laws, Regulations, Governing bodies, etc.
- Identify & Engage Expertise: Identify internal or external experts to support risk assessment and mitigations.
- Identify Potential Harms & Impacts: Assess the consequences of data breaches or misuse on individuals, the institution, and society. Examples include (non-exhaustive:
- Reputation: Damage to the credibility of researchers, institutions, or organizations.
- Harm to Research Participants: Privacy violations, identity theft, and misinterpretation of data.
- Harm to Indigenous Communities: Impact on trust, sovereignty, and ethical research practices.
- Delayed Research: Disruptions in data availability causing research delays.
- Financial Costs: High costs of remediation, investigations, and implementing security measures.
- Loss of Funding: Reduced confidence in research data leading to funding challenges.
- Theft & Illicit Transfer of Technology: Loss of competitive advantage and IP theft.
- Debarment: Potential revocation of research permissions or funding due to compliance failures.
- Criminal Liability: Potential legal consequences for non-compliance with regulations.
- National Security: Risks to national security from foreign interference or misuse of sensitive data.
- Identify & Assess Threats (Actors & Attacks):
- Identify possible threat actors (Advanced Persistent Threats - APT, Cybercriminals, Hacktivists, Insider Threats, Nation-States, Terrorist Groups, Thrill-Seekers) and evaluate their skills/capabilities, motive and opportunity.
- Identify possible attacks. The Canadian Center for Cybersecurity provides a non-exhaustive list of common tools and techniques that are used by threat actors. MITRE ATT&CK® also provides a globally accessible knowledge base of adversary tactics and techniques based on real-world observations. Researchers can consult with their respective Information Technology administrators and ISS/IST to identify applicable attacks.
- Identify & Analyze Exposures: Assess the level of exposure of data to threat actors, or potential threat actors
- Data Storage and Security: Location, security controls, volume, backup, archival, compliance
- Data Modification: User profiles, access controls, permissions, access frequency
- Access Location: Working remotely, external institutions
- Device Security: Endpoint protection, vulnerability management, encryption, access controls
- Collaboration Level: Internal/external partnerships, international collaborations
- Interfaces for Data Access: Authentication, data transfer protocols, logging
- Data Retention: Legal requirements, destruction protocols, backup and recovery
- Software Requirements: Licensing, vendor security, authentication methods
- Develop Strategies Based on Classification: Based on the assigned classification, implement tailored security measures and data management strategies to address the specific risks, ensuring appropriate levels of protection, access control, and compliance with relevant policies and regulations.