Design team members: Jerry C. Y. Chang, Zacharia Y. Jama and Peter La.
Supervisor: Professor Olga Vechtomova
Background
Information technology has transformed the way people access and process data. Large amounts of electronic reports are constantly being made accessible for public research, but utilizing these resources is becoming increasingly difficult. This is apparent in the financial industry concerning investment research. Investment research firms collect and analyze information about the economy, specific sectors and companies. Their research must be comprehensive and insightful to allow investors to make informed financial decisions. It is the task of the investment research analyst to read through company reports and retrieve the useful information that is used for analysis. However, the increasing amounts of electronic data create three challenges that make this task more difficult.
First, there can be an abundance of reports filed by a company, meaning proper assessment is labour-intensive and time-consuming. Second, it is not feasible to read all the information of interest, and some critical data will inevitably be missed. Thirdly, there is a time delay between when the data is made available and when the information is retrieved and examined by the analyst. These challenges that investment research analysts face are not being met by existing solutions such as Bloomberg, Reuters, and Google Finance which provide financial information for the masses. Investment research firms need a solution that is specific to the research of individual analysts.
Problem statement
The group will build a system that provides up-to-date financial information in a more seamless, time-efficient, comprehensive, and readily available manner to solve the challenges faced by investment research analysts.
Project
description
The
project
will
retrieve
reports,
process
them
(feature
extraction)
and
present
key
findings
to
the
end
user.
The
team
will
use
SEDAR
as
the
source
to
gather
specific
financial
reports
(Exploration
Results
and
Bid
Circular).
Once
these
reports
are
stored
in
a
local
archive,
the
system
will
automatically
extract
key
information
(features)
from
them.
This
will
be
done
using
a
combination
of
information
extraction
theories
and
techniques.
The
results
are
presented
to
the
users
in
an
interface
of
company
profiles.
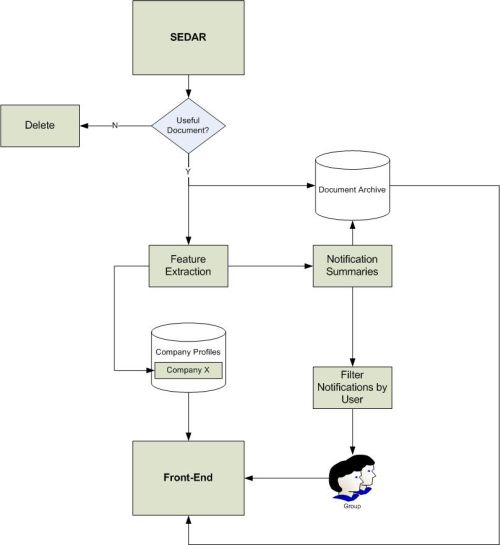
Below
is
a
diagram
of
the
overall
solution.
The
team
will
focus
its
efforts
on
demonstrating
the
capability
of
feature
extraction
for
the
fourth
year
project.
It
should
be
noted,
however,
that
the
entire
proposed
solution
would
be
required
to
meet
the
needs
of
the
problem
statement.
Design methodology
The
design
methodology
reflects
the
team
decision
to
focus
on
feature
extraction.
The
goal
of
feature
extraction
is
to
take
the
documents
in
the
local
database
and
extract
key
information
that
is
useful
to
an
analyst.
In
other
words,
this
is
the
component
that
automates
the
laborious
process
of
searching
through
all
the
data
and
interpreting
what
is
important.
The
methodology
the
team
will
follow
to
develop
the
feature-extraction
involves:
- Working with analysts to develop a template of information that needs to be extracted
- Researching different theories and techniques for automatic template filling
- Evaluating and selecting the combination of theories and techniques to use
- Designing algorithms
- Development and Implementation
- Testing
- User feedback / validation