
We train robots to solve general tasks using only images.
We train robots to solve general tasks using only images.

Wearable computer vision and deep learning are combined for real-time sensing and classification of human walking environments.
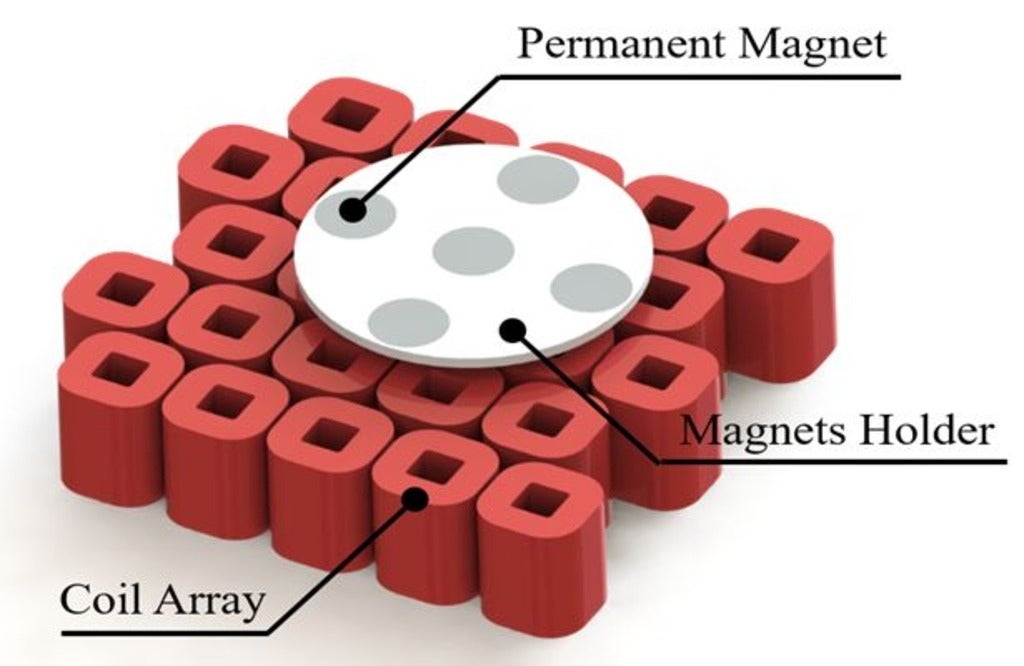
The goal of this project is to levitate a group of robots in 3D space using electromagnetic energy. MagLev (magnetically levitated) robots, providing frictionless motions and precise motion control, have promising potential applications in many fields. Controlling magnetic levitation systems is not an easy task; therefore, designing a robust controller is crucial for accurate manipulations in the 3D space and to allow the robots to reach any desired location smoothly.
This project focuses on deploying a set of autonomous robots to efficiently service tasks that arrive sequentially in an environment over time. Each task is serviced when the robot visits the corresponding task location. Robots can then redeploy while waiting for the next task to arrive. The objective is to redeploy the robots taking into account the expected response time to service tasks that will arrive in the future.

This project focuses on developing compliant control approaches for the position-controlled REEM-C which enable close, direct physical human-robot interactions that are also appropriate for social interactions.

This project aims to detect and classify physical interaction between a human and the robot, and the human's intent behind this interaction.

This work aims to ease the implementation and reproducibility of human-robot collaborative assembly user studies.

This project brings together several novel components to help solve the problem of multi-camera SLAM with non-overlapping fields of view to generate relative po

Visual navigation algorithms pose many difficult challenges which must be overcome in order to achieve mass deployment.