Researchers in artificial intelligence have developed an innovative way to identify a range of anti-social behaviour online. The new technique, led by Alex Parmentier, a master’s student at Waterloo’s David R. Cheriton School of Computer Science, detects anti-social behaviour by examining the reaction to a post among members of an online forum rather than examining features of the original post itself.
The spectrum of anti-social behaviour is broad and current artificial intelligence models are unable to form an understanding of what is being posted, Alex explained.

Alex Parmentier is pursuing a Master of Mathematics in Computer Science. His research is focused primarily on applications of AI and machine learning towards the understanding and direction of the flow of information online. In particular, he is developing models that leverage trust relationships between users to create better content recommendations and detect malicious content and misinformation.
“Often, when attempting to detect unwanted behaviour on social media, the text of a user’s comment is examined. Certain forms of anti-social speech — for example, bullying via sarcastic mockery — are difficult for AI systems to detect, but they’re not missed by human members of the online community. If you look at their reactions, you may have a better chance of detecting hate speech, profanity and online bullying.”
Actions and comments that are disruptive to others can provide strong clues as to what is deemed anti-social. In fact, some researchers define anti-social behaviour precisely as behaviour that is disruptive to a community. Using this approach, an online community’s reaction to comments could be a key factor in understanding and detecting what is anti-social.
To develop the method, Alex first downloaded more than six million comments from Reddit, a popular social news-sharing site that has an active culture of commenting and discussion. Reddit comments are threaded — organized in a tree-like format — so it’s easy to classify an original comment from those that are in response to it.
In this study, a parent comment was defined as any comment that has been replied to directly. A child comment is a direct reply to another comment, and descendants of any parent are all the comments in the subtree that are rooted at the parent.
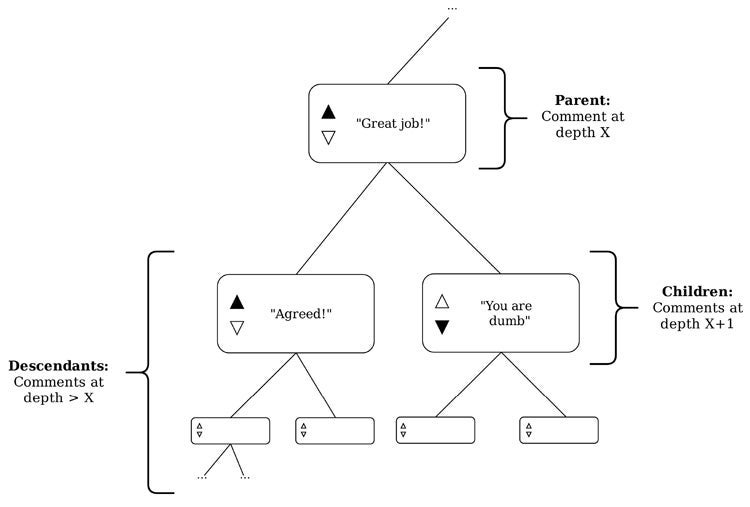
This illustration shows an example of a parent comment, its children and their descendants.
Reddit has multiple “subreddits” — discussion forums within Reddit that cater to specific interests. The data set analyzed for this study contained only comments that were posted during January 2016 on the following subreddits — /r/politics, a subreddit for political discussion, /r/movies, a subreddit where films are discussed, /r/worldnews that hosts discussion about current events, /r/AskReddit, a subReddit where people pose questions to the Reddit community, and /r/IAmA, a subreddit in which members can ask a particular person anything.
Alex trained models on words and phrases extracted from responses to comments within those subreddits to try to predict whether a parent comment that prompted a reaction in children coments and other descendants was likely to contain hate speech, profanity and negative sentiment.
“Prediction accuracy ranged from a high of 79% to a low of 58% — so it was a bit of a mixed bag,” Alex said. “Often, we found it was difficult to improve these scores by tinkering with classifiers or parameters, perhaps indicating that our feature collection procedures or the amount of data collected was insufficient to support certain prediction tasks. That said, we found that the best-faring tasks involved predicting the presence hate speech in a parent comment.”
While these results show that establishing highly reliable classifiers is still somewhat elusive, they also indicate that this direction of AI research has much promise.
“Our model can be used to easily figure out the users who are provoking responses from an online community that look like they’re harming other users and either give their comments less exposure or flag them for other users to be aware,” Alex said. “By learning how a community reacts to currently detectable anti-social behaviour, we can begin to learn what a typical reaction to anti-social behaviour looks like, which can allow for the detection of more complex anti-social behaviour involving sarcasm and unfamiliar references in someone’s comment based on the reactions of others.”